Vladimír Maršík - Jiří Horák
Institut geoinformatiky
VŠB - Technická univerzita Ostrava
tř. 17. listopadu
708 33 Ostrava - Poruba
E - mail: vladimir.marsik@vsb.cz , jiri.horak@vsb.cz
The main goal of the TRANSCAT project (Integrated Water Management of Transboundary Catchments) will be to create an operational and integrated comprehensive Decision Support System (DSS) for optimal water management of catchments in borderland regions. The project should facilitate an implementation of EU Water Framework Directive.
The process of requirement specifications for the target DSS was made in Unified Modeling Language (UML). The model includes description of basic requirements, classification of end-users and description of interactions between users and the system where the use case diagrams were applied. The second part of the analytical phase of future DSS modeling was the creation of the class diagram.
The final model contains several hundreds of classes and more then one hundred use cases in fifty packages.
The language differences were taken in account in the model. Translation of elements names and descriptions was represented by tagged values. For the specification of differences on the national level were special UML stereotypes introduced. New UML stereotypes were introduced to express spatial character of classes and relationships between them.
Hlavním cílem projektu TRANSCAT (Integrated Water Management of Transboundary Catchments) je vytvoření operativního a integrovaného komplexního Systému podpory při rozhodování (Decision Support System, DSS), který by měl prospět optimálnímu managementu vodního hospodářství v příhraničních povodích v kontextu zavádění Rámcové směrnice EU pro vodní politiku (EU Water Framework Directive).
Pro specifikaci požadavků na systémový návrh budoucího DSS byl použit jazyk UML (Unified modeling language). Formalismem UML byl vytvořen pojmový popis (funkční požadavky), obsahující:
- popis požadavků, které tvoří vlastní zadání DSS v rámci projektu TRANSCAT
- klasifikace všech uživatelů, kteří mohou vstupovat do interakce se systémem
- popis interakcí konkrétních uživatelů se systémem pomocí USE CASE diagramů
Jako druhá nutná součást analytické fáze modelování byl vytvořen pojmový slovník (datové požadavky), obsahující statický pohled na data pomocí CLASS DIAGRAMu.
Vytvořený model zohledňuje kromě popisu stávajících činností a datových sad také Rámcovou směrnici vodní politiky Evropské unie, která významným způsobem ovlivňuje způsob fungování vodohospodářského sektoru.
Z důvodu vlastního zaměření projektu TRANSCAT bylo v rámci modelu nutné zohlednit národní specifika. Překlad názvů jednotlivých prvků modelu do různých jazyků je reprezentován pomocí tzv. "tagged value". Pro popisy rozdílů v datových sadách na území různých států byl zaveden stereotyp vztahu generalizace. Další stereotypy byly v modelu zavedeny pro potřebu vyjádření prostorové povahy některých modelovaných tříd.
Finální model obsahuje několik stovek tříd a více než sto use case diagramů v asi padesáti balíčcích. Tvorba rozsáhlého UML modelu vyžaduje vhodný CASE nástroj, který práci urychluje a zpřehledňuje. Před vlastním zahájením práce na modelu bylo proto provedeno porovnání dostupných nástrojů tohoto typu. Konečné rozhodování bylo potom provedeno podrobným srovnáním mezi nástrojem Poseidon for UML a mezi Enterprise Architect
TRANSCAT je výzkumný projekt podporovaný Evropskou Komisí pod Pátým rámcovým programem. Hlavním cílem projektu je vytvoření operativního a integrovaného komplexního Systému podpory při rozhodování (Decision Support System, DSS) v zájmu optimálního managementu vodního hospodářství v příhraničních povodích - v kontextu zavádění Rámcové směrnice EU pro vodní politiku (EU Water Framework Directive).
DSS je specifickým druhem interaktivního počítačového systému, který pomáhá řídícím a rozhodovacím pracovníkům používat data, dokumenty, znalosti a modely za účelem správného pochopení a řešení problémů a vydávání správných rozhodnutí.
Jedna z důležitých počátečních fází projektu TRANSCAT (work package 3) se zabývá specifikací požadavků a analýzou stávajícího stavu. Součástí tohoto balíčku je také práce na prototypu TRANSCAT DSS, přičemž cílem prototypu je ověřit praktické možnosti realizace systému, nalézt a zmapovat možná úskalí a v neposlední řadě také motivovat potenciální koncové uživatele. Garantem za tento balíček je VŠB-TU Ostrava.
Jako modelovací jazyk byl pro potřeby analýzy a návrhu TRANSCAT DSS vybrán UML. Vybraným UML CASE nástrojem podporující všechny etapy analýzy a návrhu je systém Enterprise Architect firmy Sparx.
Pomocí dotazníků, rozeslaných vybraným potenciálním uživatelům jsme zjišťovali:
Rovněž byly připraveny formuláře pro popis dostupných datových zdrojů v jednotlivých oblastech. Popis datových zdrojů byl prováděn ve formě základního přehledu (název, měřítko, formát, identifikace, použití), na který pak navazoval detailní popis metadat v samostatném souboru pro každý datový zdroj. Metadata jsou připravena podle ISO 19115. Později předpokládáme vložení těchto metadat do metainformčního systému.
Dále byl připraven na základě rozboru legislativy a administrativních zvyklostí přehled jednotlivých zainteresovaných organizací (koncových uživatelů i těch, kteří pouze ze systému profitují) spolu s popisem jejich aktivit. Tyto přehledy byly zaslány partnerům spolu s žádostí o doplnění jejich potenciálních uživatelů a popis jejich aktivit. Zatím se na základě odpovědí podařilo upravit přehled koncových uživatelů a jejich aktivit pro uživatele v Řecku, Německu, Norsku, Rusku, Bulharsku, Itálii a Polsku. Tyto přehledy budou ještě dále doplňovány a upřesňovány.
Na základě získaných informací bylo možné zahájit analytické práce. Jako vyjadřovací prostředek jsme se rozhodli využívat UML. UML je dnes standardní jazyk pro modelování (analýzu i design) a jeho použití je vcelku samozřejmé. Práce v UML by byla značně zdlouhavá a pro rozsáhlejší projekty nepřehledná bez použití vhodného CASE nástroje.
V rámci našeho projektu jsme se rozhodli pro použití nástroje Enterprise Architekt firmy Sparx. Tomuto rozhodnutí předcházelo porovnání mezi tímto produktem a produktem Poseidon for UML firmy Gentleware.
Použití CASE nástroje usnadňuje všechny kroky analýzy a podstatně ji ulehčuje. Bez CASE nástroje by se velmi těžko udržovaly vazby mezi jednotlivými částmi modelu, nebylo by možné postupovat metodou postupného zjemňování ani automatické generování dokumentace. Navíc na provedenou analýzu může navázat ve stejném prostředí také etapa návrhu systému, včetně generování kódu a databáze.
V rámci výuky Objektově orientovaného programování a jazyka UML na Institutu geoinformatiky VŠB TU Ostrava se již používal nástroj Posseidon for UML. Před začátkem prací na analýze TRANSCAT DSS jsme se rozhodli ověřit jeho vhodnost pro tento projekt a případně se rozhodnout pro alternativu v jiném CASE nástroji.
Pro modelování v UML je dnes k dispozici široká paleta desítek nástrojů s různou mírou funkčnosti v cenovém rozsahu 0 až několik tisíc USD. Jako vhodný nástroj se brzy začal jevit produkt Enterprise architect australské firmy Sparx. Proto jsme provedli jejich porovnání. Výsledek porovnání některých parametrů lze vidět v tabulce č. 1.
| Enterprise architect | Posseidon for UML |
Operační systém | MS Windows | Platform independent, implemented in Java |
Uložení modelu (repozitory) | Ve standardní relační databázi | do souboru |
Export do .XMI | ANO | ANO |
Podpora všech diagramů UML | ANO | ANO |
Podpora více-uživatelské práce | ANO | NE (bude ve verzi Enterprise) |
Generování dokumentace | RTF, HTML | HTML (UMLdoc plugin) |
Generování SQL DDL | ANO | ANO, vyžaduje doplňkový modul |
Generování kódu | ANO | ANO |
Podpora verzí, sledování kvality, testování | ANO | NE |
Plná cena (verze profesional) | 149 USD * | 699 USD * |
* oba výrobci nabízejí slevy pro studenty a pro školství.
Tab. 1 Srovnání některých vlastností produktů Enterprise architect a Posseidon for UML
Oba srovnávané programy jsou velmi kvalitní CASE nástroje pro UML, dostupné v různých verzích s četnými rozšířeními. Pro analytické práci na projektu TRANSCAT jsme se rozhodli používat Enterprise architect. Důvodem je to, že aplikace je velmi rychlá i při práci s velkými modely, standardně nabízí víceuživatelskou práci. Jako velmi užitečné se ukázalo generování dokumentace ve formátu rtf, pro snadnou možnost dalšího zpracování. Silnou vlastností je ukládání modelu do relační databáze. Díky tomu lze například pomocí dotazování v jazyce SQL generovat specifické typy výstupních sestav.
Vlastní analýza TRANSCAT DSS obsahuje tyto části:
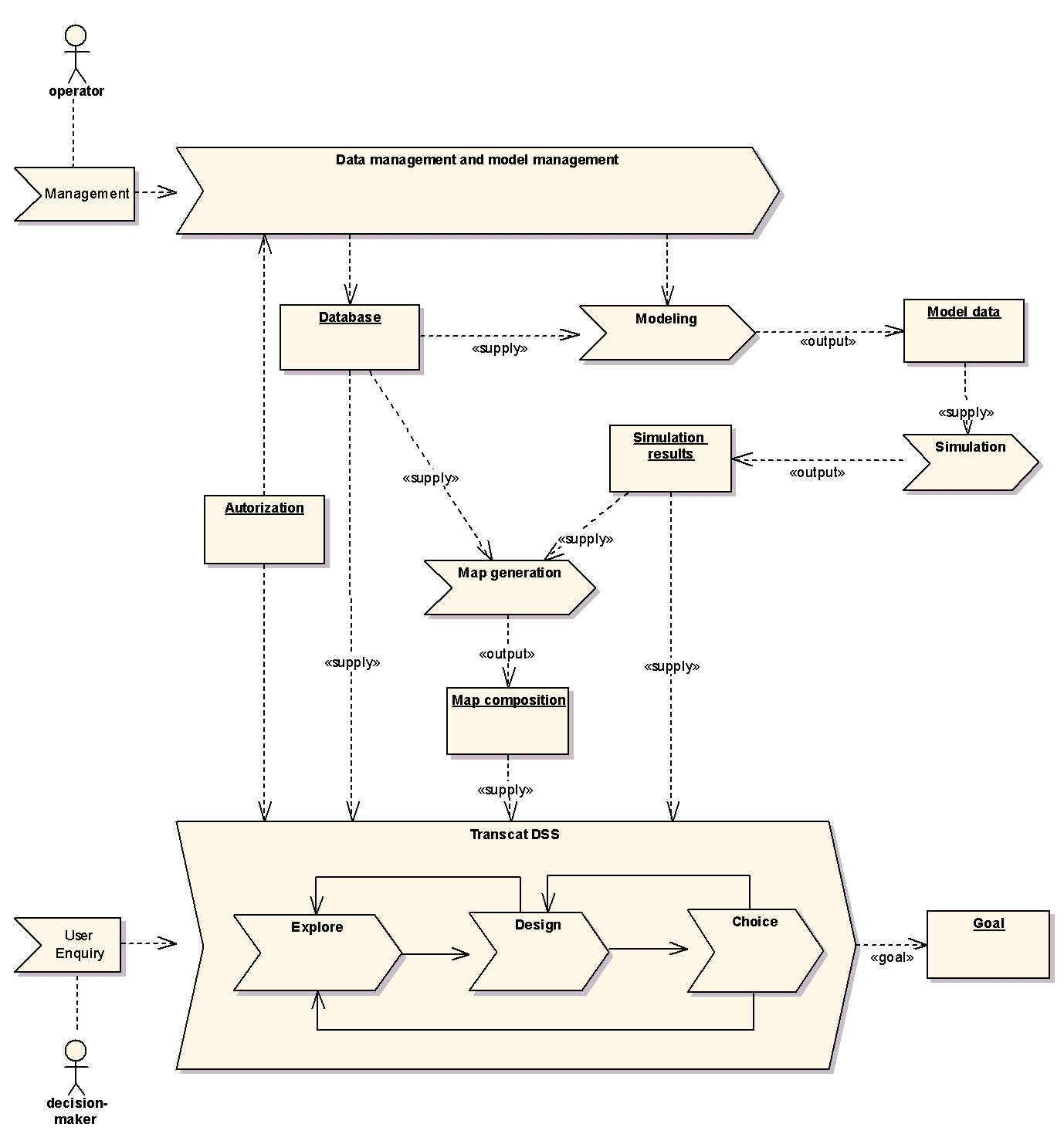
Business process UML diagram byl do analýzy zařazen pro objasnění předpokládané činnosti navrhovaného DSS. Tento typ digramu, který je uživatelským rozšířením UML, byl definovaný autory Hans-Erik Eriksson a Magnus Penker. Diagram velmi zjednodušeně popisuje co je předmětem činnosti informačního systému, jaká data a zdroje vstupují a co je výsledkem. Přitom procesy jsou transformace vstupních dat na výstupní, systému je aktivován pomocí událostí. Business process diagram objasňující uvažovanou činnost navrhovaného TRANSCAT DSS je na obrázku číslo 1.
Obr. 1 UML business process model (click on image to see it in original resolution)
1. Popis požadavků na systém
Popis požadavků je řešen pomocí prvků requirements, viz obrázek č.2. Popis požadavku je součástí poznámky. Například v poznámce požadavku 3.1 Software architecture se můžeme dočíst: The software system will be functioning on the Internet, ensuring both adequate operation of the geographically distributed managerial system, and the participation of a possibly broad scope of agents/actors, including citizen participation, with preservation of appropriate data security, decision competence, as well as efficiency of the system operation.
Požadavky jsme rozdělili do několika skupin. Počet požadavků je relativně malý, neboť primární zadání není příliš konkrétní.
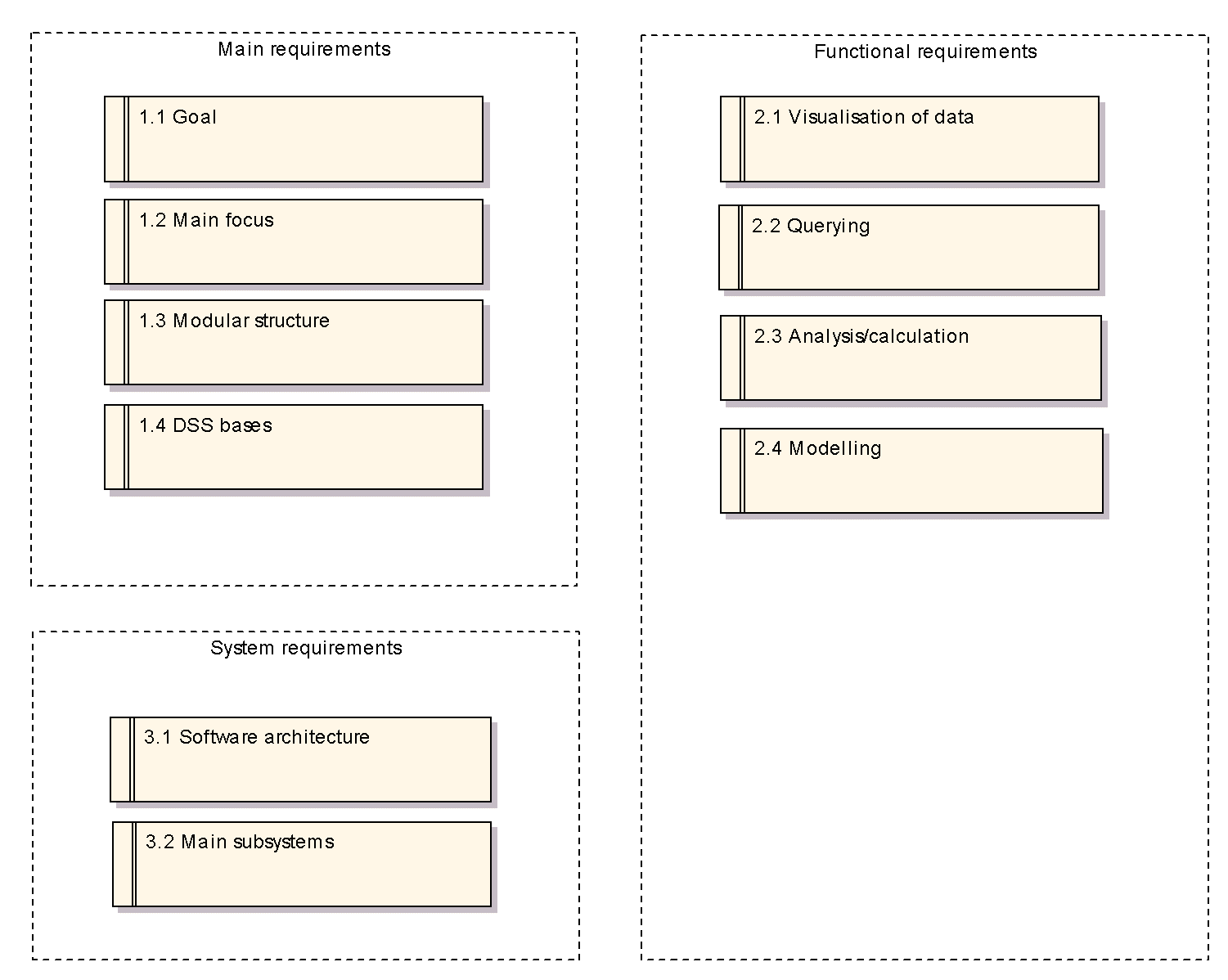
Obr. 2 Klasifikace požadavků pomocí prvků Requirement (click on image to see it in original resolution)
2. Předpokládaní uživatelé systému
Jedním z prvních kroků v analýze bylo vytipování potenciálních uživatelů systému a jejich rozdělení na koncové uživatele (end-users) a uživatele sekundární (benefitors). Každý uživatel je v UML modelovaný pomocí prvku Actor, viz obrázek č.3.
Předpokládané uživatele jsme rozdělili do dvou skupin. End-users jsou ti jenž budou se systémem přímo pracovat, budou moci jej využívat pro své rozhodování v praxi. Druhou skupinu "benefitors" tvoří uživatelé, kteří se systémem přímo nepracují, ale budou moci využívat některých jeho výstupů, případně budou ovlivněni jeho provozem.
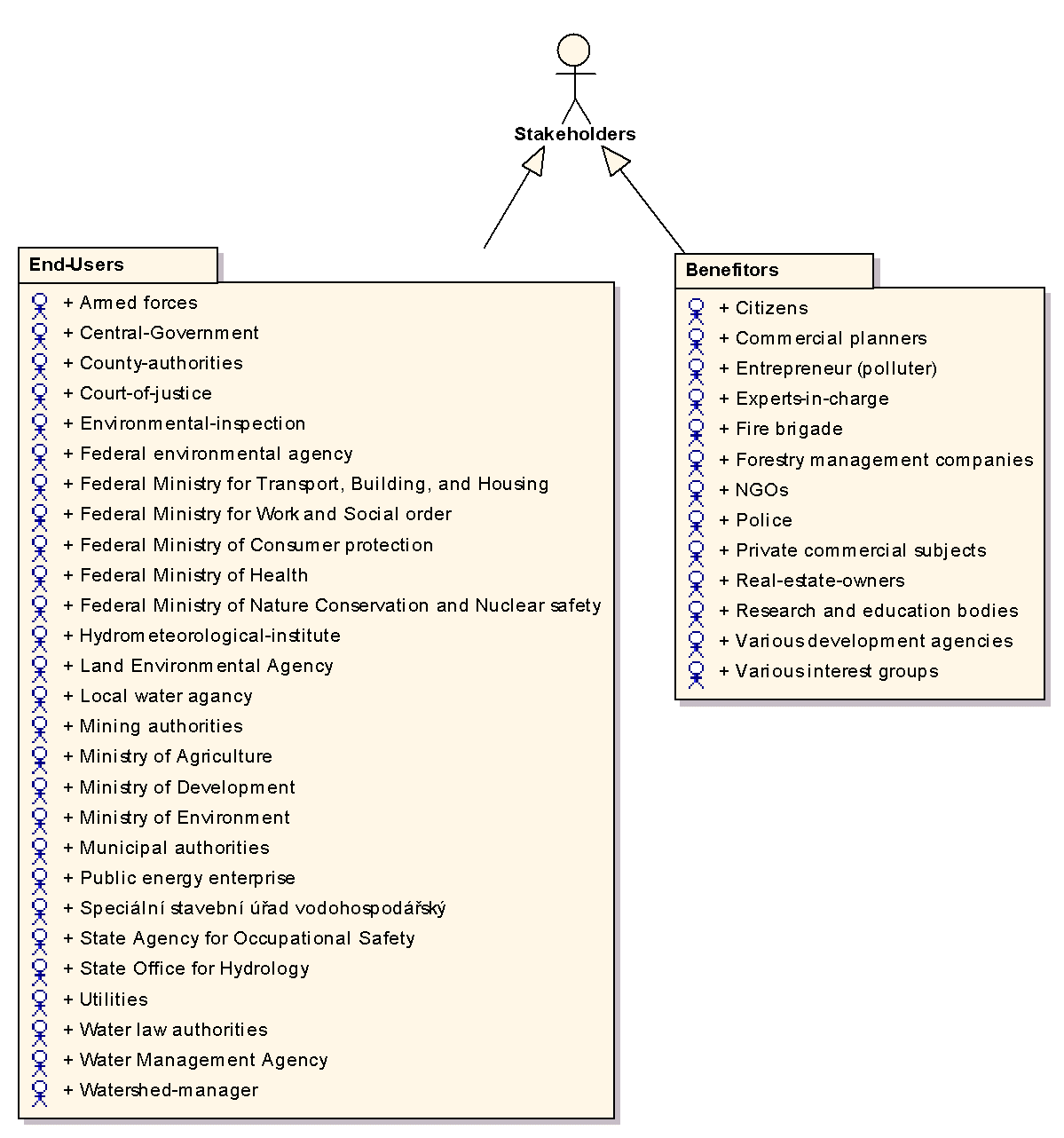
Obr. 3 Uživatelé systému modelovaní pomocí prvků Actor (click on image to see it in original resolution)
3. Popis činností, interakce s uživatelem - diagram případů užití
Případů užití bylo velké množství a proto bylo nutné případy užití organizovat do balíčků, jak je patrné z obrázku č. 4. V rámci balíčků jsou potom rozlišovány případy užití, které mají povahu souhrnu užitných činností (tj.případy užití, které se dále člení na další) a případy užití, které tvoří listy tohoto hierarchického stromu. Teprve tyto listy jsou hledanými případy užití, které odpovídají konkrétním funkcionalitám systému. Fragment tohoto diagramu je na obrázku č. 5.
U jednotlivých případů užití jsme identifikovali rovněž národní prostředí, ve kterém jsou tyto případy potvrzené (viz CZ, GR na obr.5).
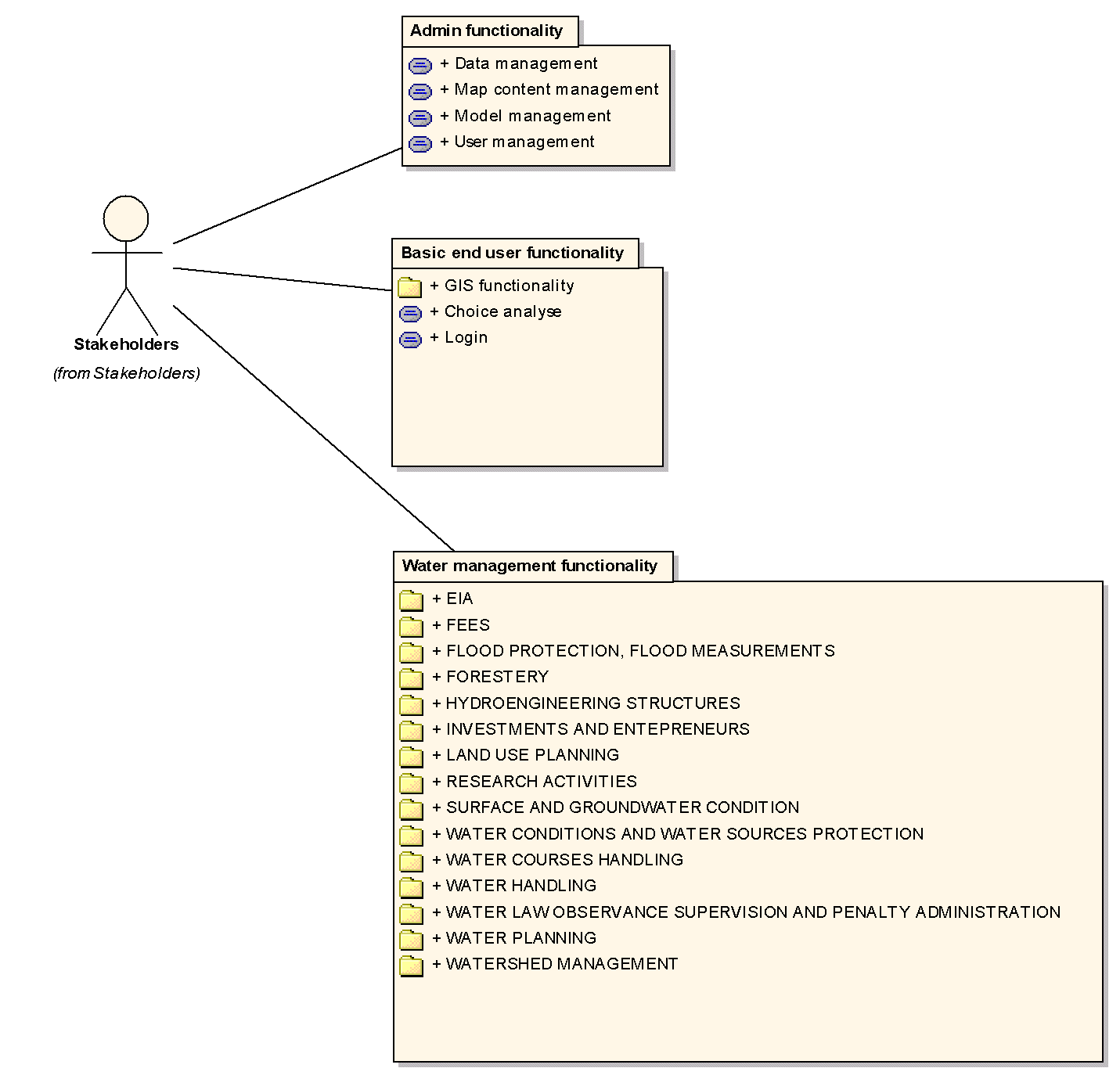
Obr. 4 Základní členění užitných činností (click on image to see it in original resolution)
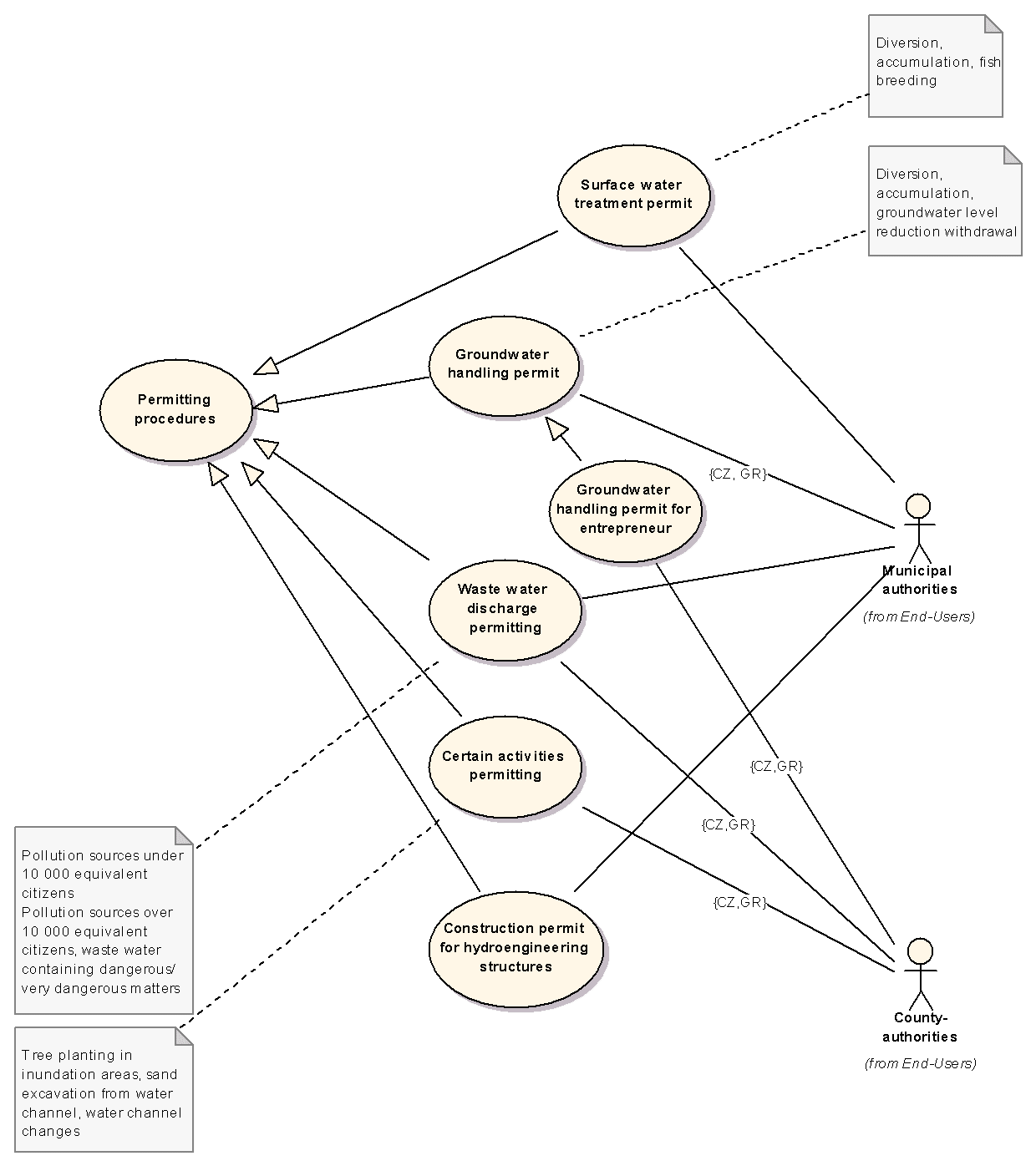
Obr. 5 Fragment diagramu užitných činností skupiny water handling (click on image to see it in original resolution)
4. Datový model - Class diagram
Vytvořený logický datový model se zaměřuje především na popis datových zdrojů stávajících a potřebných pro podporu dříve analyzovaných funkcionalit systému.
Model je rozdělen do několika balíčků, viz obrázek 6.
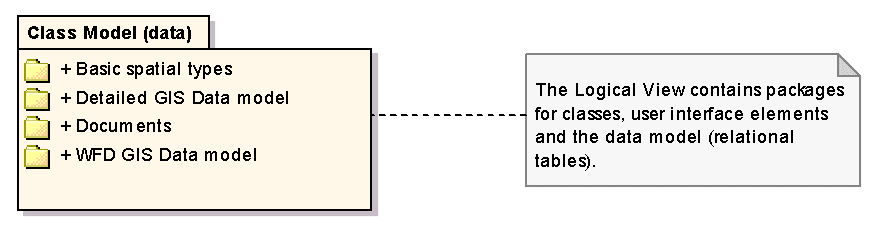
Obr. 6 Balíčky s jednotlivými částmi datového modelu (click on image to see it in original resolution)
Každý z těchto balíčků je poměrně obsáhlý, proto aby zajištěna srozumitelnost jsou balíčky hierarchicky složeny z dalších menších balíčků. Na obrázku 7 je zachyceno složení balíčku "Detailed GIS Data model".
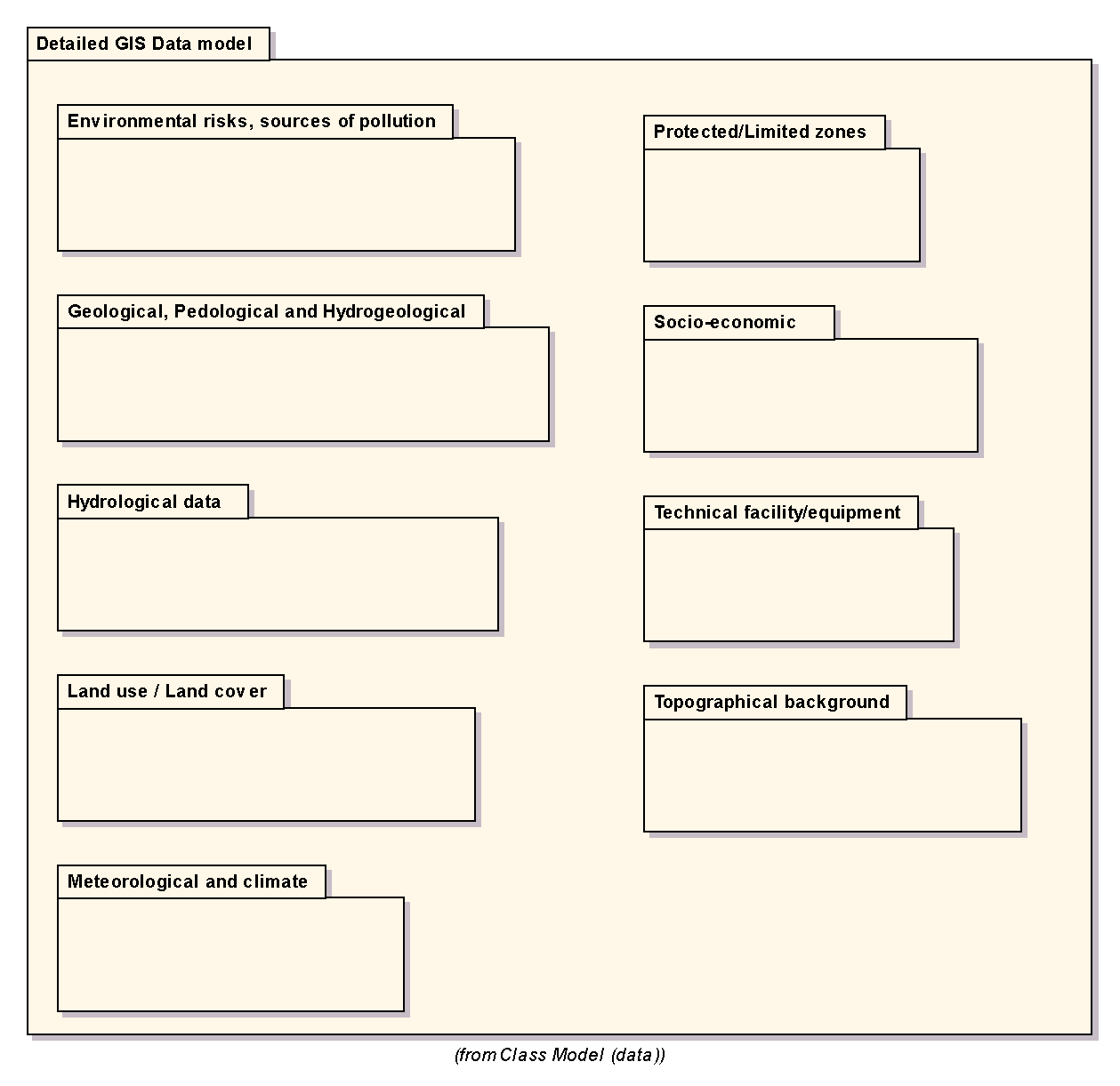
Obr. 7 Detailní logický datový model se skládá z devíti balíčků (click on image to see it in original resolution)
Každý balíček obsahuje alespoň jeden diagram typu Class diagram, reprezentující datový model a popis jednotlivých tříd. Příkladem logického datového modelu zahrnutého do balíčku "Detailed GIS data" je "Topographical background". Fragment tohoto diagramu je na obrázku č.8. Zde je pomocí vztahu kompozice zachyceno členění topografického pozadí na topografické mapy, data získaná leteckým a družicovým snímkováním a na data o terénním reliéfu. Třída topografických map je pomocí vztahu generalizace rozdělena na topografická data dostupná na území jednotlivých států. Pro tento účel byly vytvořeny stereotypy (tzn. rozšíření UML) "GR_part" pro data dostupná na území Řecka, "CZ_part" pro data dostupná na území České republiky atd. Třída "CZ topo maps" potom reprezentuje již konkrétní mapové podklady, resp. jejich agregaci.
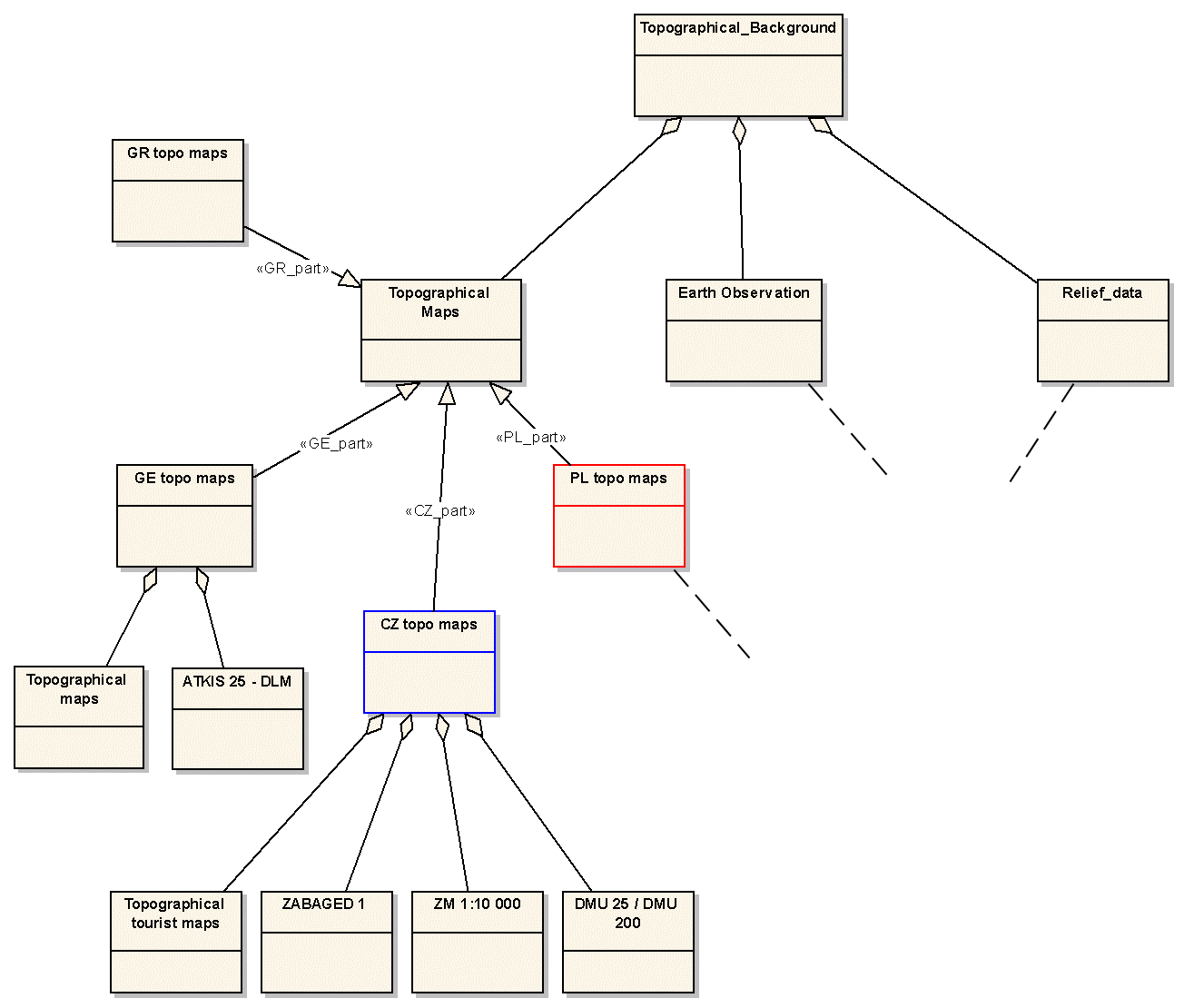
Obr. 8 Část logického datového model, balíček Topographical background (click on image to see it in original resolution)
Dalším příkladem jednoho z důležitých logických datových modelů vytvořených v rámci analýzy je model dat potřebných do modelu proudění podzemní vody, viz obrázek 9.
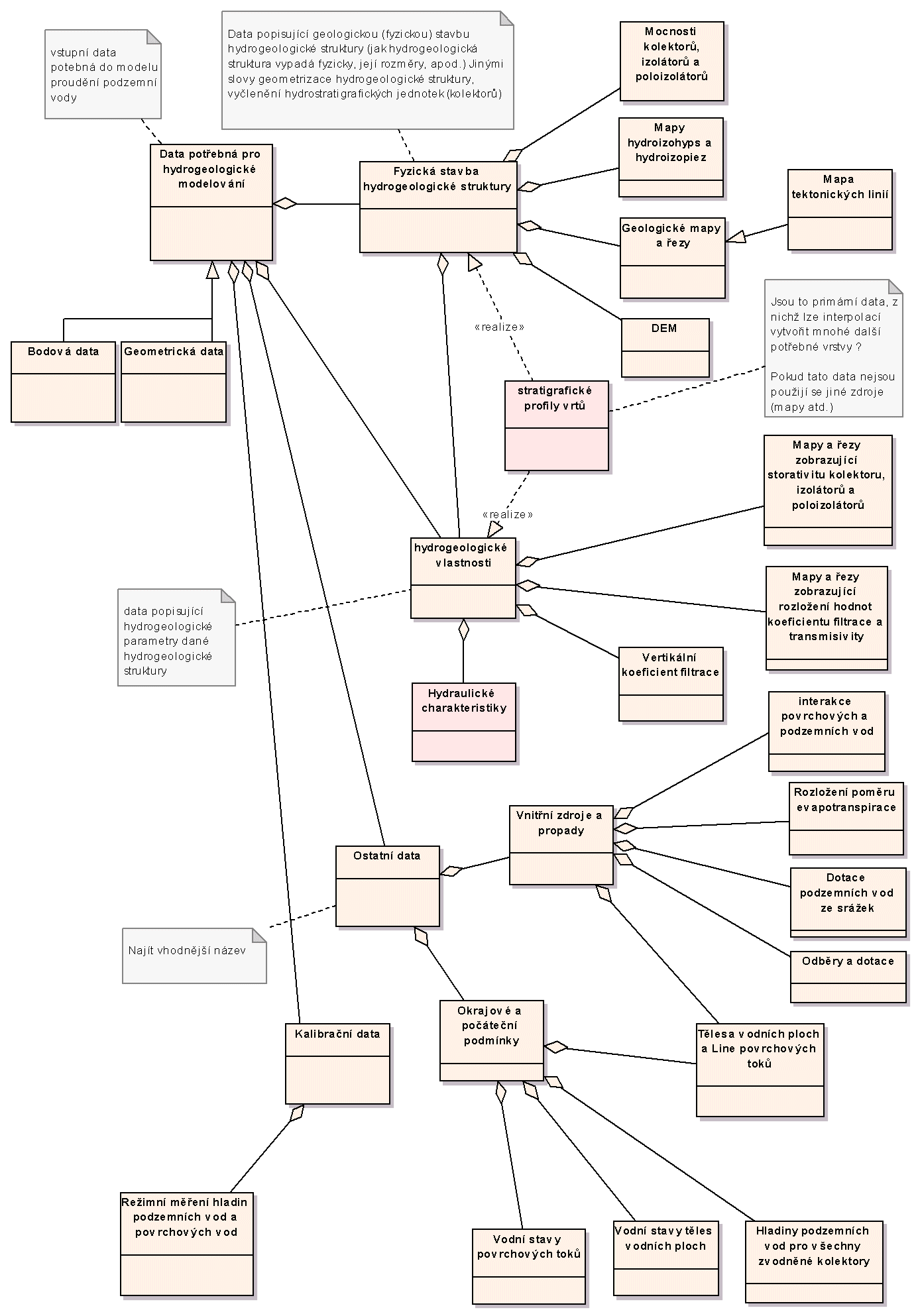
Obr. 9 Detailní logický datový model - data potřebná pro hydrogeologické modelování (click on image to see it in original resolution)
V balíčku WFD GIS Data model jsou zahrnuty dílčí logické datové modely popisující hydrologická data jak jsou chápána v rámci směrnice Water Framework Directive (WFD) [5,6]. Příkladem je logický datový model povrchových vod na obrázku č. 10 nebo logický datový model požadovaných mapových kompozic zobrazujících informace o stavu povrchových a podzemních vod na obr. 11.
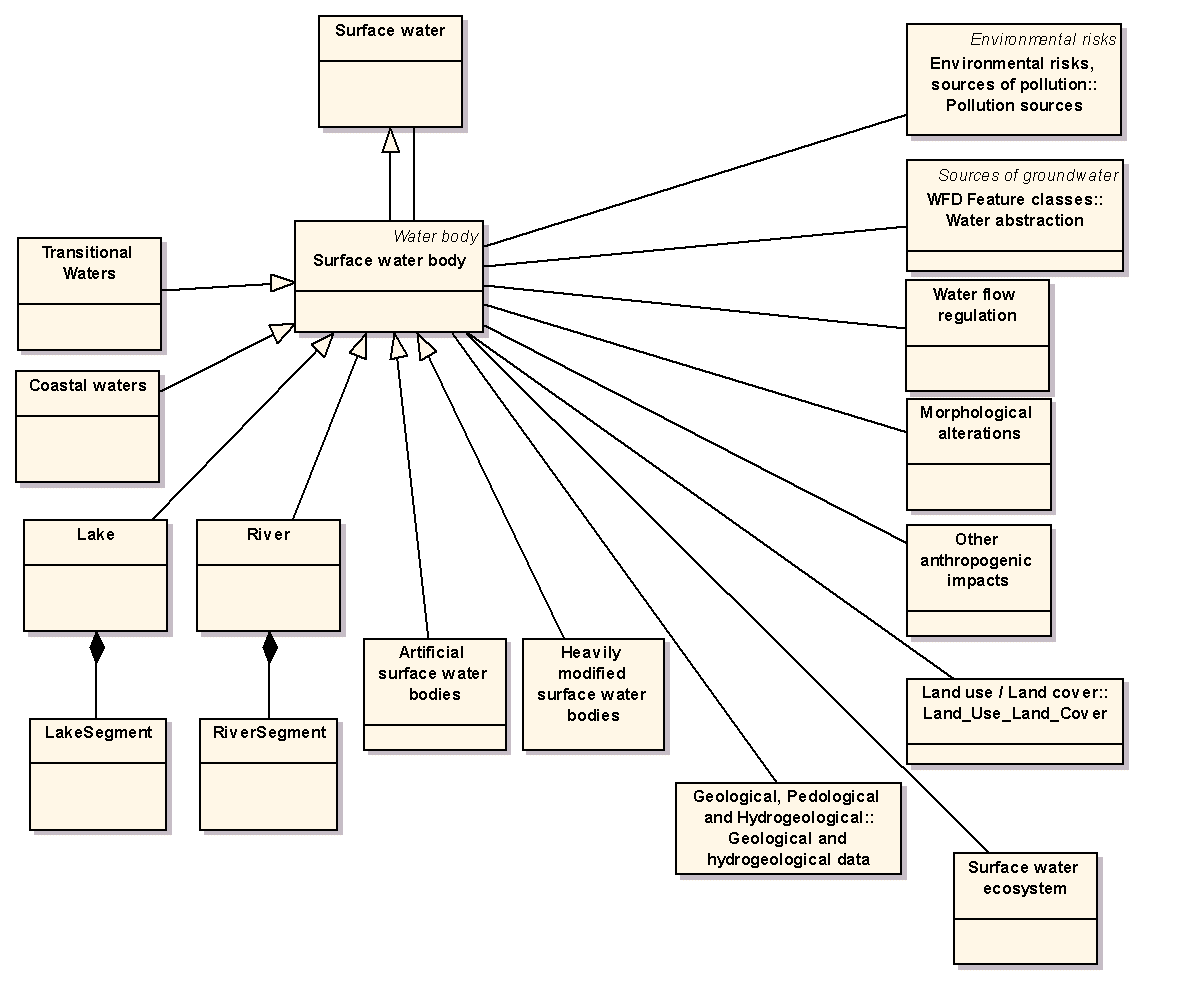
Obr. 10 Logický datový model povrchových vod, zpracovaný podle WFD (click on image to see it in original resolution)
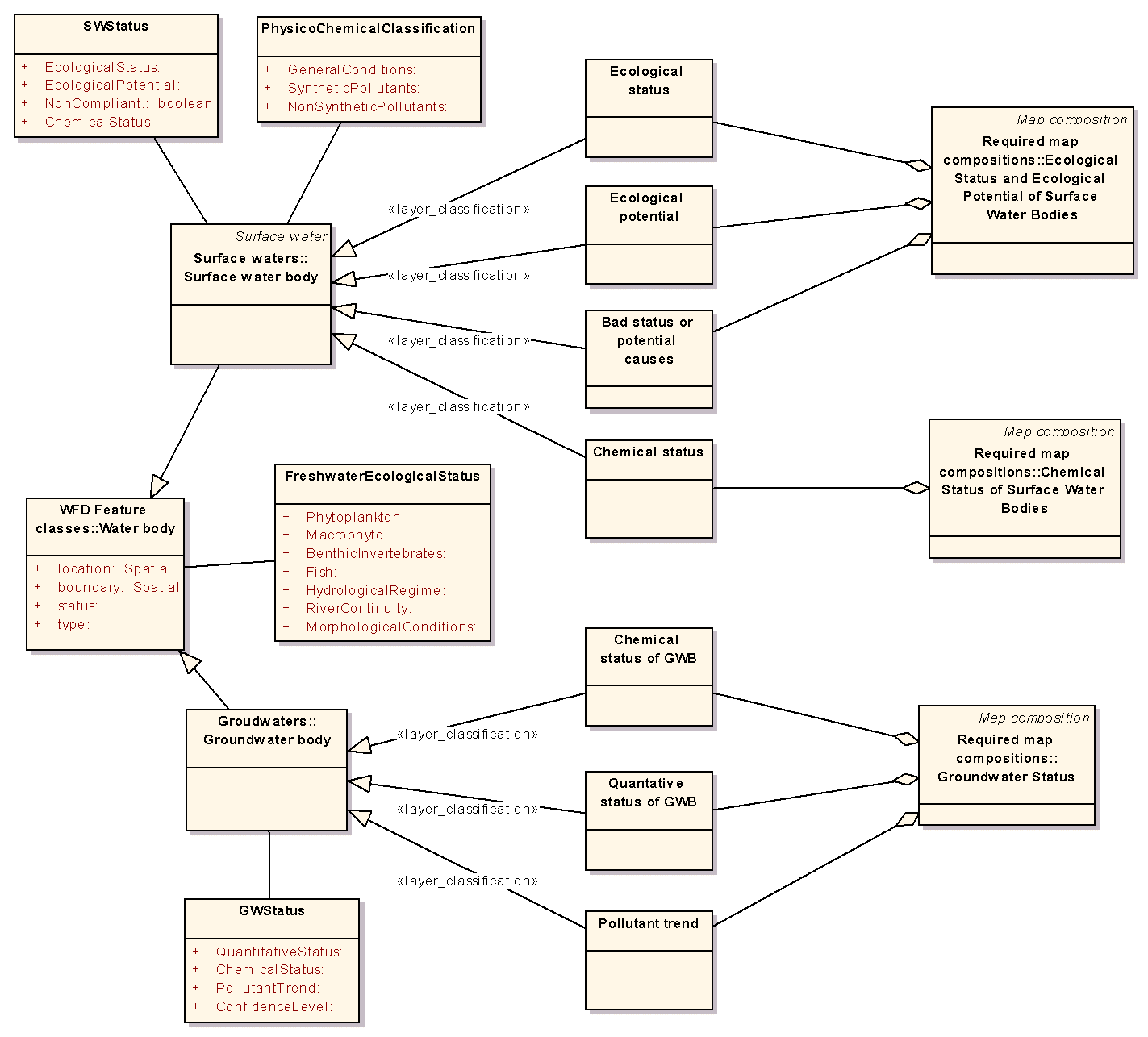
Obr. 11 Logický datový model mapových kompozic zobrazujících informace o stavu povrchových a podzemních vod, podle požadavků WFD. (click on image to see it in original resolution)
V rámci modelu jsme se pokusili se širším záběrem o zmapování základních rozhodovacích činností v oblasti správy vod povrchových i podzemních. Popis těchto činností postupně zjemňovaný na "listové" případy užití by měl být základem pro TRANSCAT DSS. V rámci uvažovaného DSS není samozřejmě možné řešit celou nesmírně komplexní problematiku. V dalším zjemňování analýzy je nutno se zaměřit již na některé konkrétní oblasti podpory rozhodování. Celková "mapa", vytvořená pomocí hierarchie případů užití má svůj význam i v tom, že pomáhá konkrétní oblast zaměření DSS vymezit. Tomuto napomáhá i modelování vazeb mezi nalezenými uživateli a skupinami činností.
V části logického datového modelu jsme se pokusili pomocí prostředků UML class diagramu zachytit požadavky pramenící z WFD. Zároveň jsme se pokusili vytvořit konkrétní logické datové modely vstupů potřebných pro hydrogeologické modelování. Další část logického datového modelu je tvořena inventarizací dostupných (GIS) dat.
Vytvořený datový model je v této chvíli tvořen celkem 50-ti diagramy, 250-ti třídami a 135-ti případy užití.